Data sources
Website
ChatGPT trained on your website in minutes!
The website data source allows you to create a custom ChatGPT bot that learns from the content of your website in minutes! Perfect for creating customer support bots, sales assistants, documentation bots, and more.
Once your bot has all your content, you can easily embed it on your site as a chat widget or iFrame.
Adding a website data source to your bot
You can add a website data source to your bot to let it use content from any website in its answers.
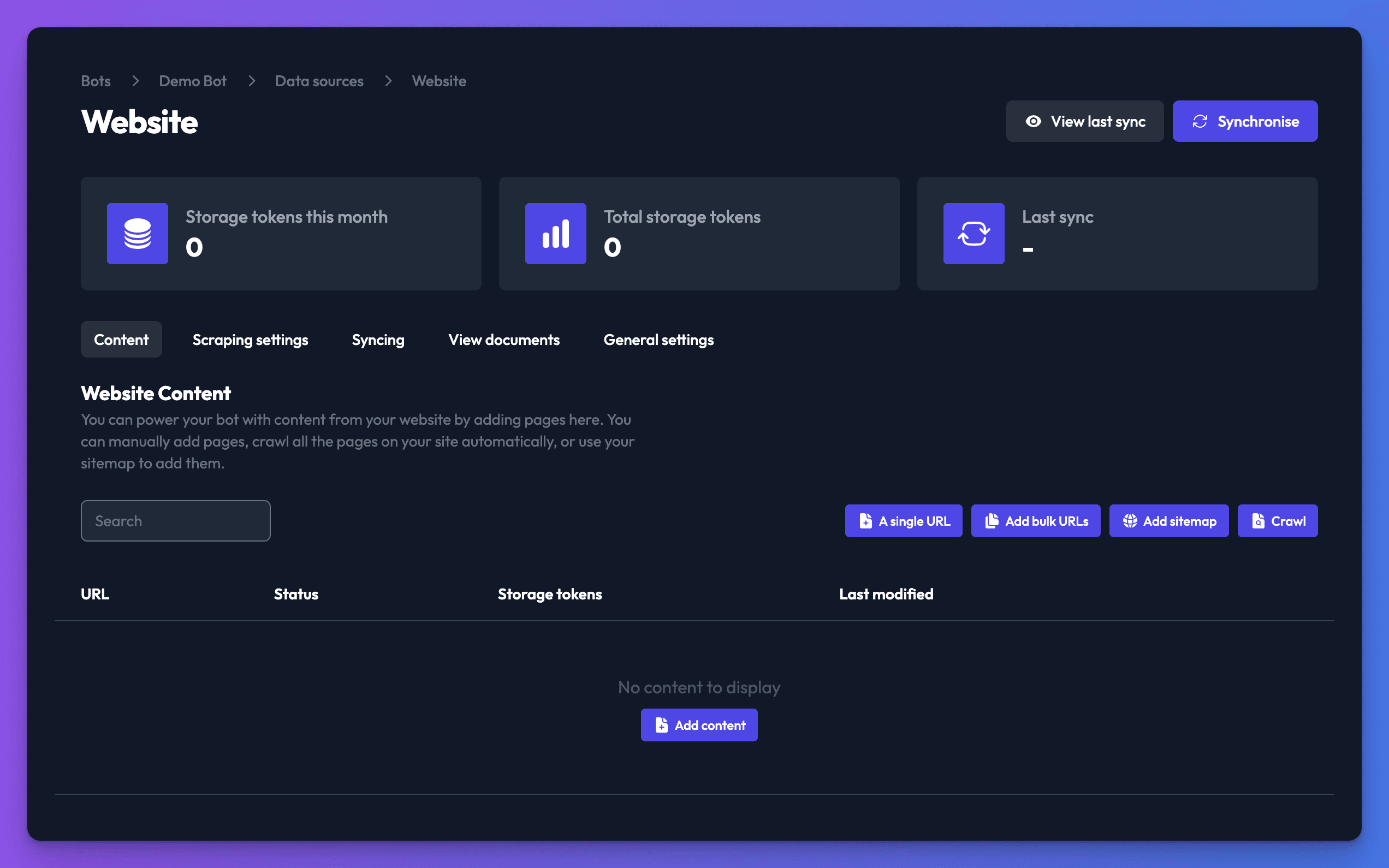
- Navigate to the Data sources tab on your bot's dashboard page. Click the New data source button, select Website and click Create data source.

- On the web page data source settings page that appears, you can now add web pages to be included in your bot. There are a number of ways to add pages to your website data source:
- "A single URL" - Add a single URL to the data source
- "Add bulk URLs" - Add multiple URLs at once
- "Add sitemap" - Add a link to a sitemap to add all the URLs it contains
- "Crawl" - Add a single URL and crawl the website to discover other links. Will add a maximum of 600 URLs.
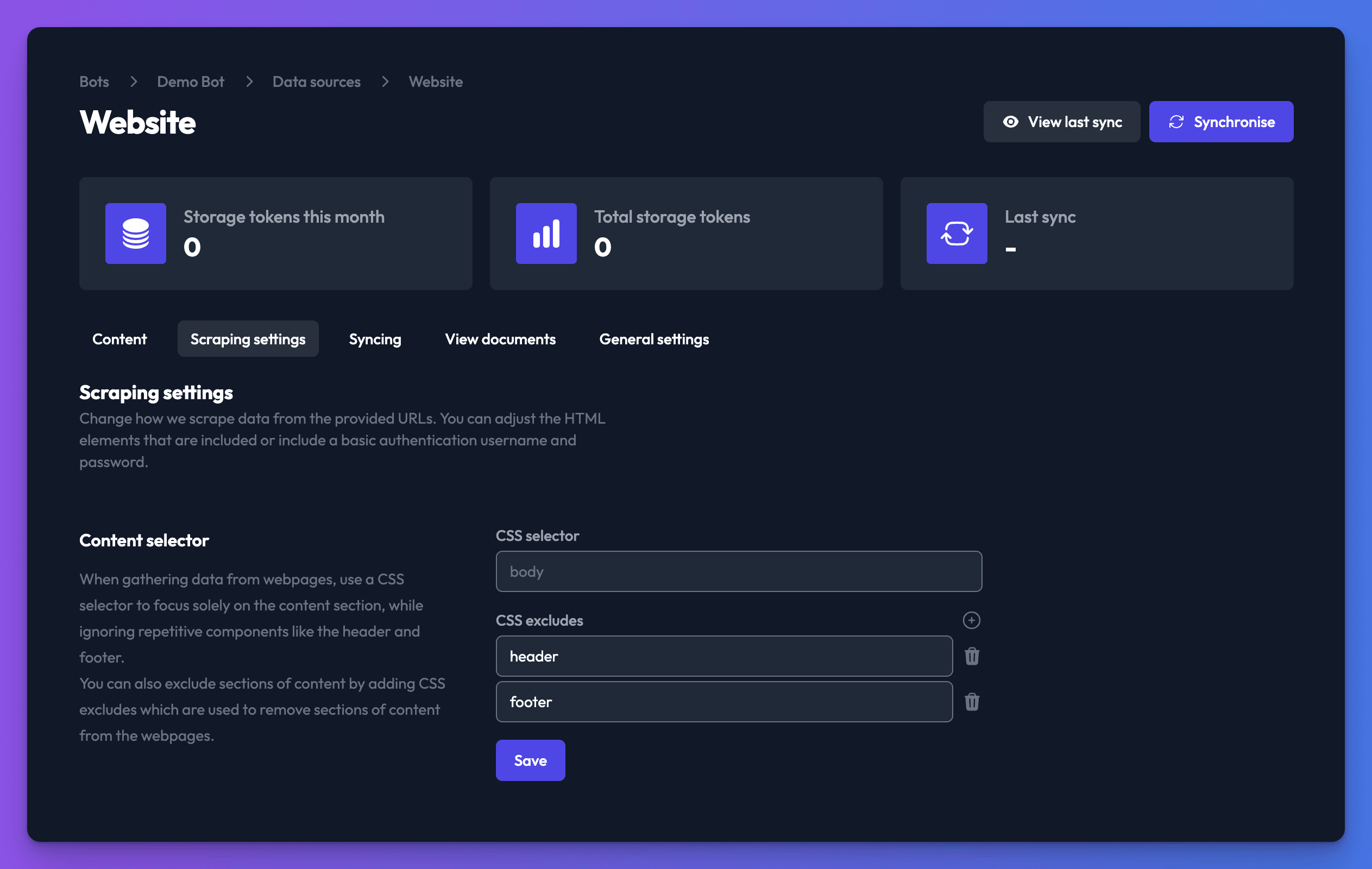
- Check the Scraping settings (see below). It's generally a good idea to set a content selector to control which parts of the web page we load into your data source. You can also exclude sections of content. Header and footer are excluded by default.
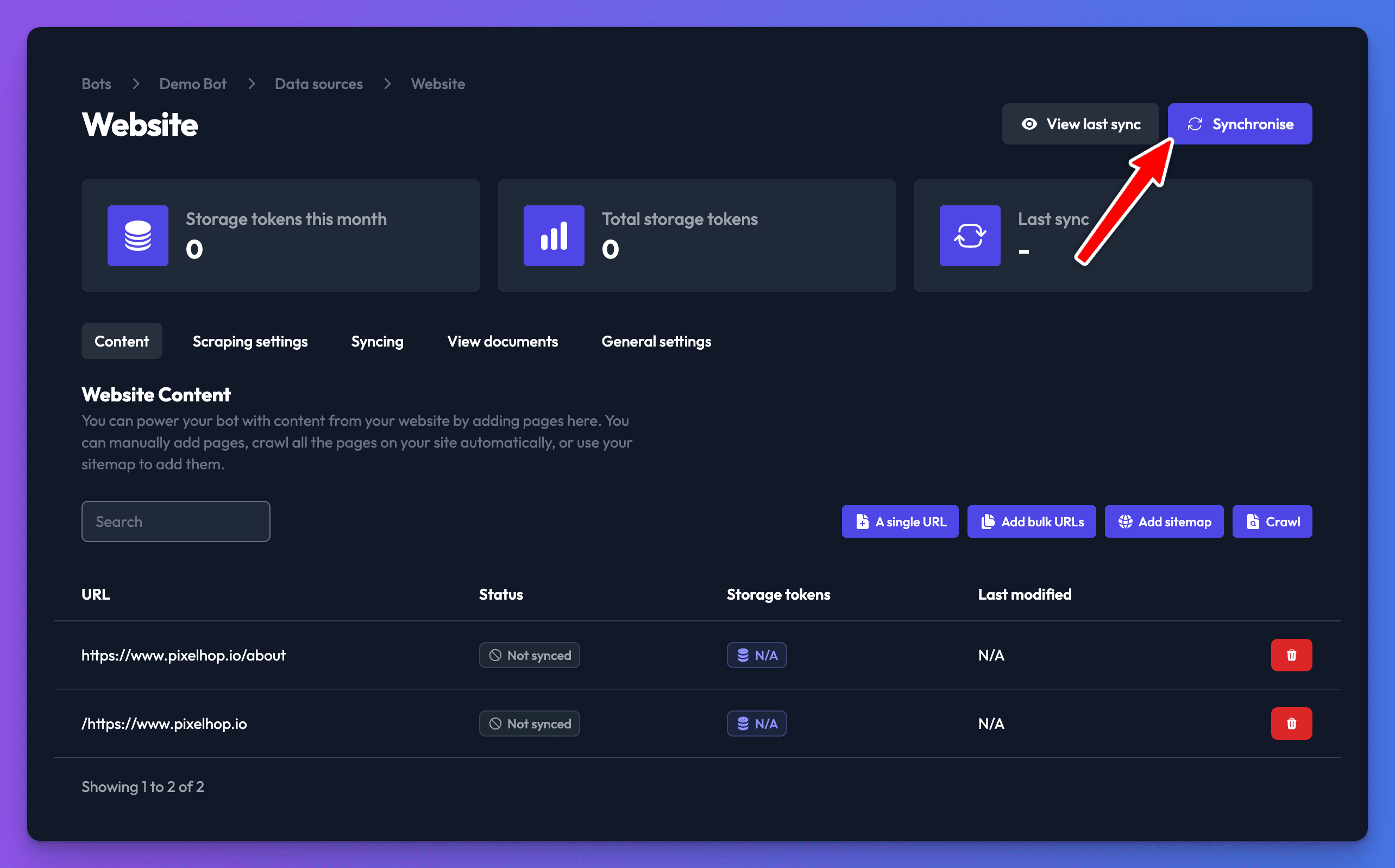
- Once you have added all the pages you want to include, click Synchronise. Your web page data source will begin to synchronise and will be ready for the bot to use shortly.
Keep your bot up to date
💡 Set up automatic syncing so your bot always has the latest content. Learn more →
Do you support automatic crawling?
Yes, you can automatically crawl a website to discover all of its content. From within the web data source settings page, click the Crawl button:
Add the address of the site you would like to crawl and click the "Crawl" button:
Be patient
Please be patient while your crawl runs. Depending on the size and speed of the site, it can take a number of minutes.
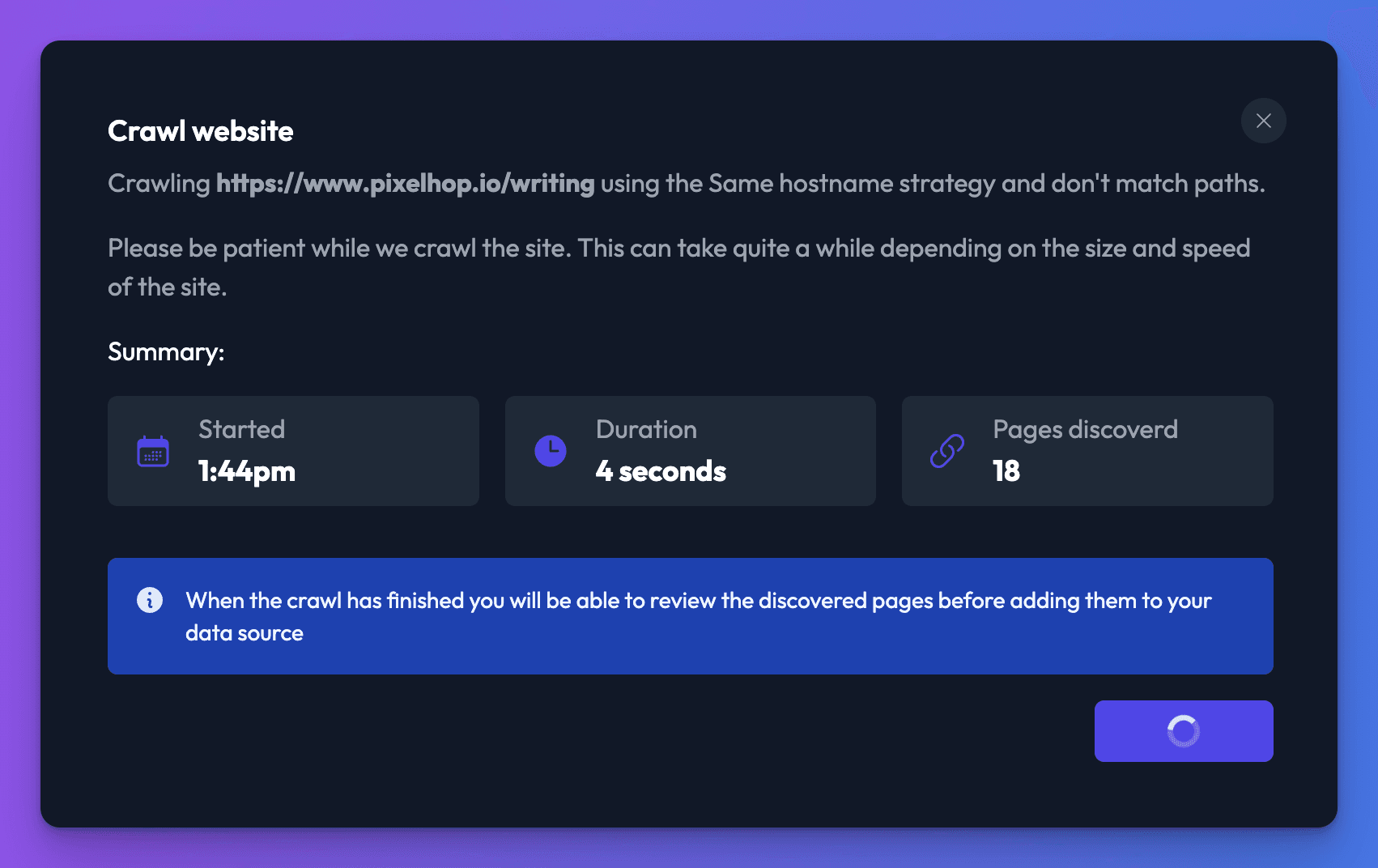
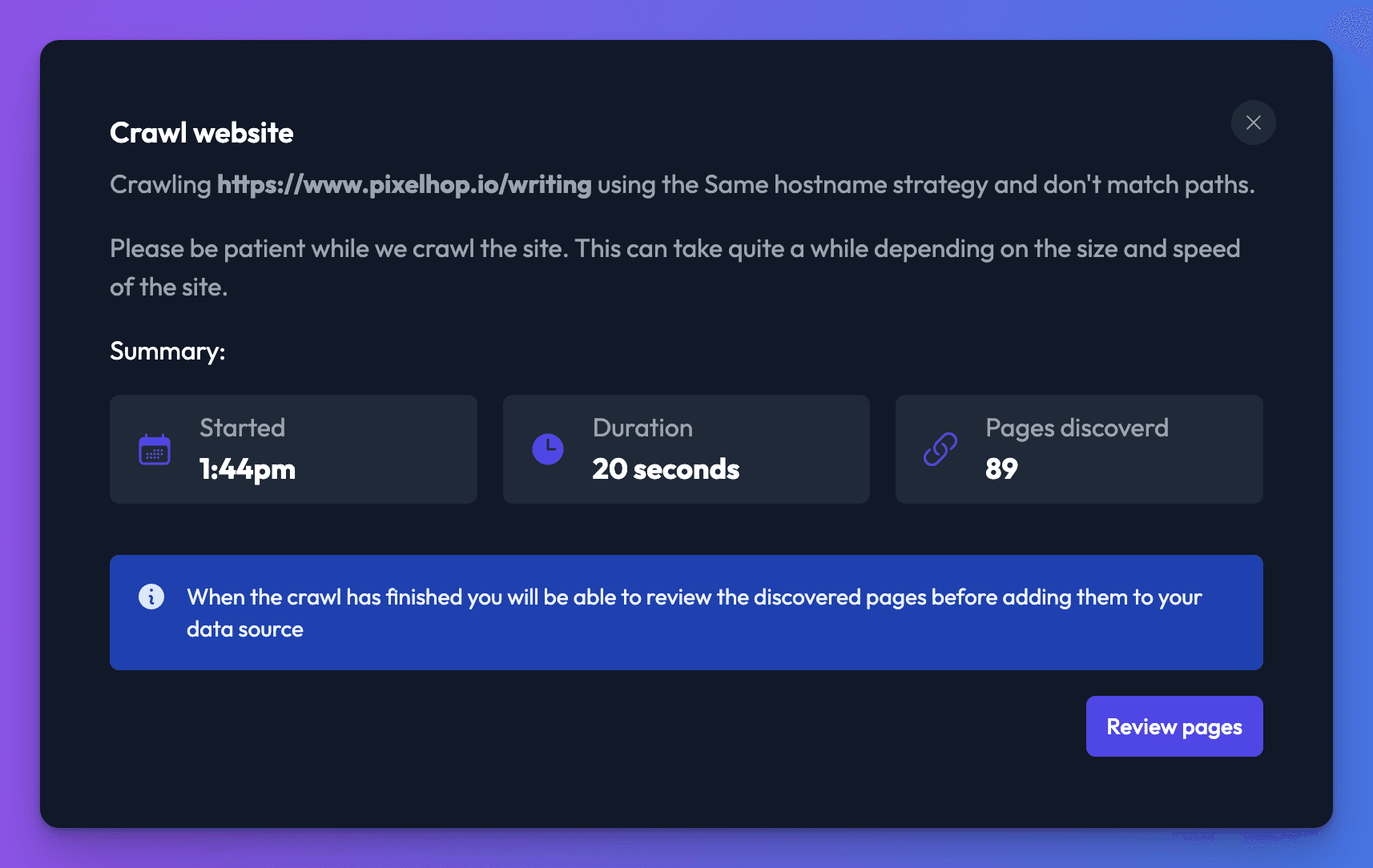
When the crawl has finished, you will be able to see all of the URLs discovered before adding them to your data source. Click Review pages.
You can search through the discovered URLs using the search bar and pagination at the bottom. Click the toggles next to the URLs you do not want to include. Once all unwanted URLs are turned off, you can proceed by clicking the Add number URLs.
Synchronise the data source.
Scraping settings
There are few advanced settings which do require some additional knowledge, the first option is the CSS selector, this allows you to control which parts of your website we load.
The default is body, which is a safe default as it's present in all webpages. Header and footer are excluded as they are generally duplicated across all pages and sync would use up far more storage tokens than required. Now, we won't go into too much detail here, but this is certainly worth a little research and a review of your site's structure to work out the optimum CSS selector to use. It's worth trying this out on a single URL to fine tune it before attempting to sync your entire site.
Please be aware that the structure of your website could vary between sections, and since the CSS selector can only be defined per data source, it may be helpful to split out differing sections into separate data sources so that the CSS selector can be varied as required.
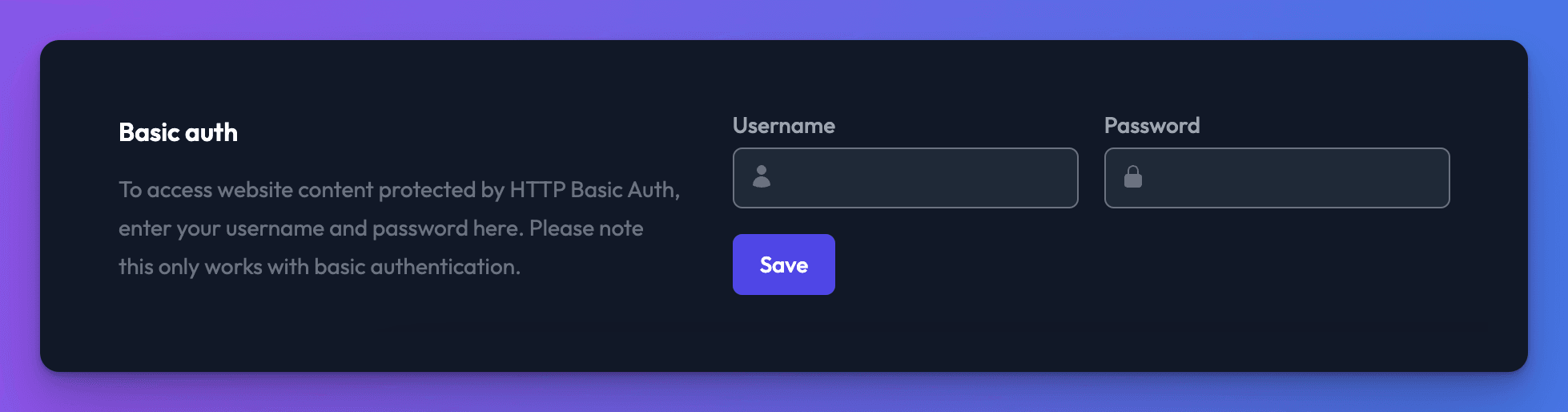
If your website is protected by Basic Auth, we also provide inputs to provide the username and password so our syncing system can access protected content within your website.